🌙
✨ Biography 📄 CV I am a Ph.D. student at Shanghai Jiao Tong University and Shanghai AI Lab . My advisor is Prof. Yali Wang . I received my B.S. degree in Computer Science and Technology from China University of Mining and Technology (Beijing) in 2024.
Currently, I am a Research Intern at Meituan LongCat M17 . I have also spent wonderful time as a research intern at Alibaba ,Huawei Noah's Ark Lab , Shanghai AI Lab , SIAT , and Samsung .
My research interests include:
🔗 Unified Multimodal Understanding & Generation 🌐 Omni-modal Representation Learning 🌍 World Model 🎬 Video Understanding & Generation
🔥 I'm actively pursuing intern opportunities in Unified Multimodal Understanding and Generation or World Model. Feel free to reach out for potential collaborations.
📑 Publications* indicates equal contribution
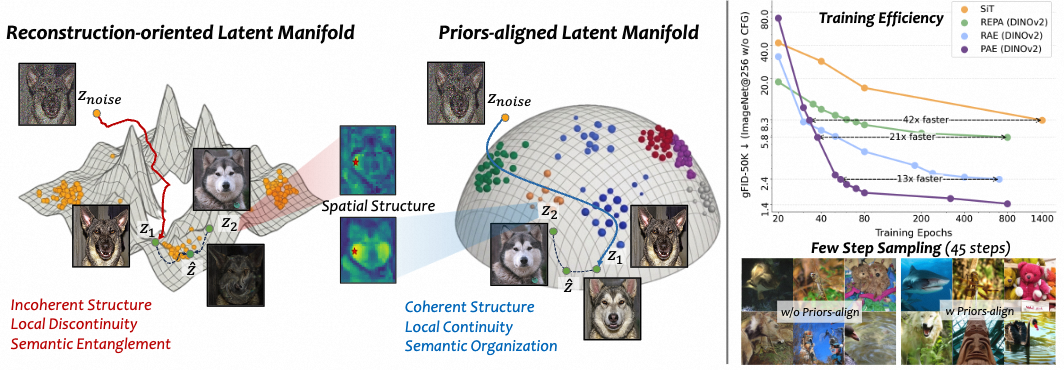
What Matters for Diffusion-Friendly Latent Manifold? Prior-Aligned Autoencoders for Latent Diffusion
Zhengrong Yue , Taihang Hu, Mengting Chen, Haiyu Zhang, Zihao Pan, Tao Liu, Zikang Wang, Jinsong Lan, Xiaoyong Zhu, Bo Zheng, Yali Wang
Arxiv 2026 New
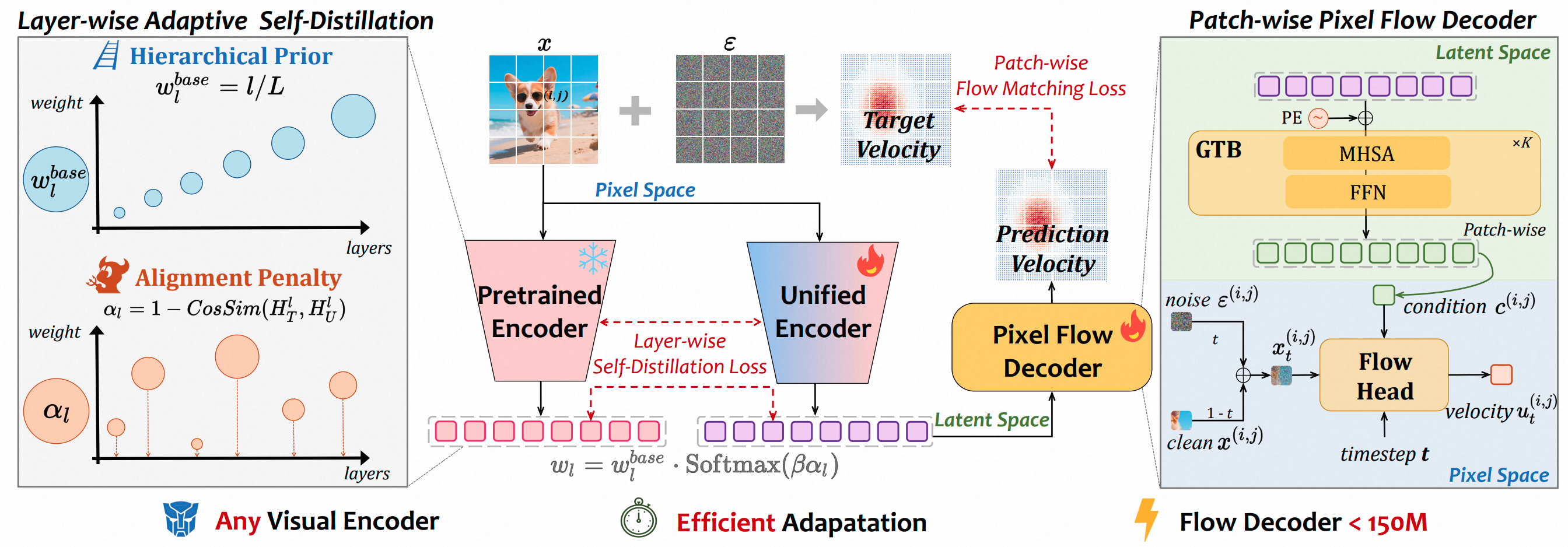
UniFlow: A Unified Pixel Flow Tokenizer for Visual Understanding and Generation
Zhengrong Yue , Haiyu Zhang, Xiangyu Zeng, Boyu Chen, Chenting Wang, Shaobin Zhuang, Lu Dong, Kunpeng Du, Yi Wang, Limin Wang, Yali Wang
ICLR 2026 New
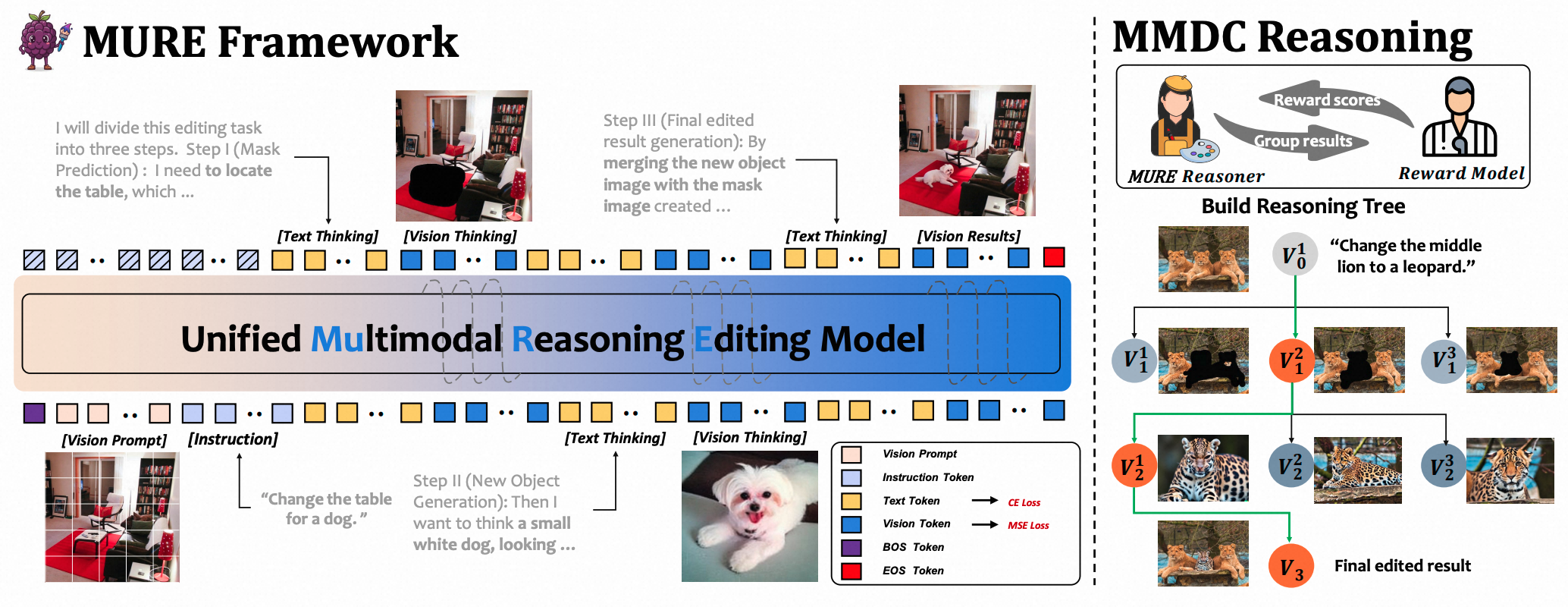
Beyond Textual CoT: Interleaved Text-Image Chains with Deep Confidence Reasoning for Image Editing
Zhentao Zou*, Zhengrong Yue *, Kunpeng Du, Binlei Bao, Hanting Li, Haizhen Xie, Guozheng Xu, Yue Zhou, Yali Wang, Jie Hu, Xue Jiang, Xinghao Chen
Arxiv 2025 New
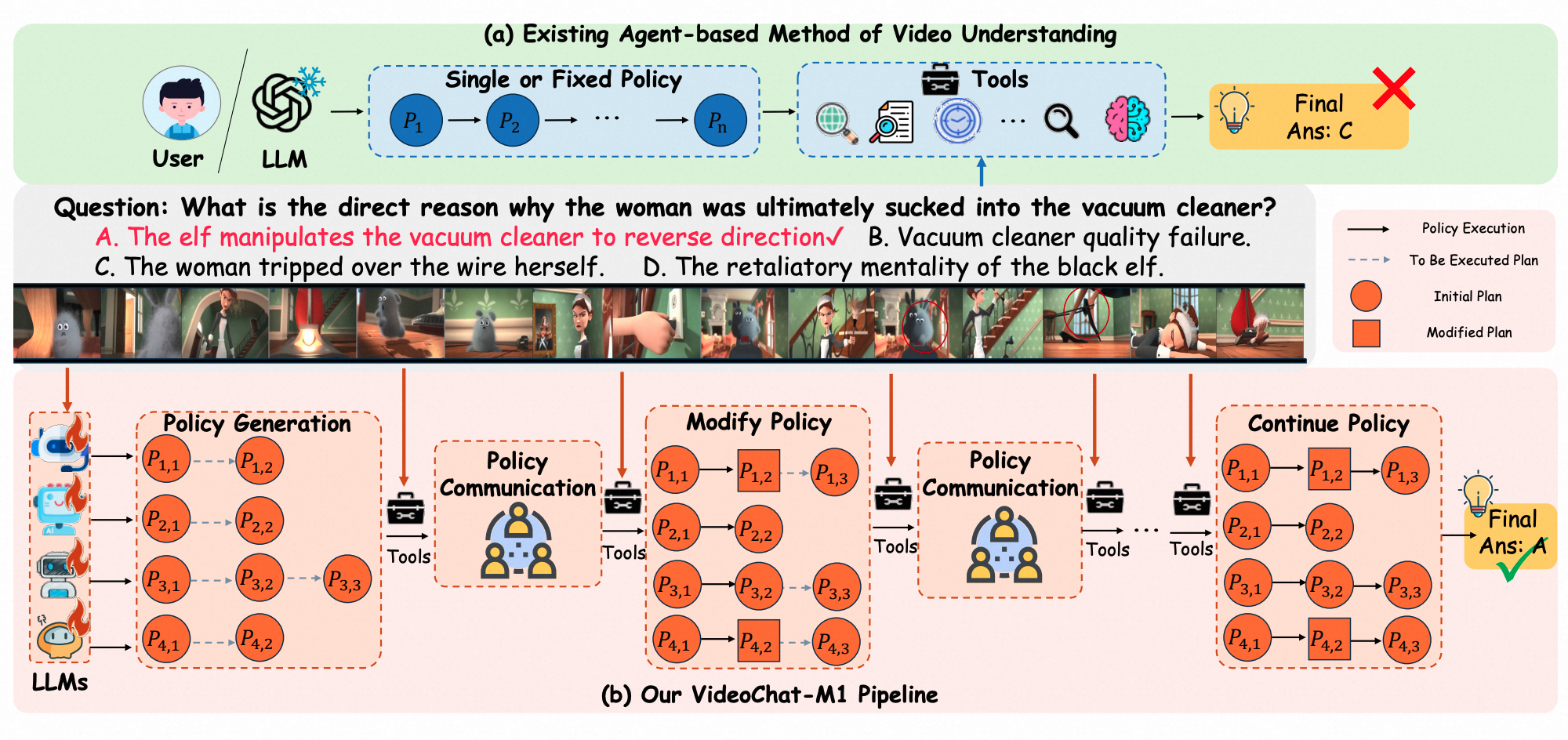
VideoChat-M1: Collaborative Policy Planning for Video Understanding via Multi-Agent Reinforcement Learning
Boyu Chen*, Zikang Wang*, Zhengrong Yue *, Kainan Yan*, Chenyun Yu, Yi Huang, Zijun Liu, Yafei Wen, Xiaoxin Chen, Yang Liu, Peng Li, Yali Wang
CVPR 2026
VideoChat-A1: Thinking with Long Videos by Chain-of-Shot Reasoning
Zikang Wang*, Boyu Chen*, Zhengrong Yue *, Yi Wang, Yu Qiao, Limin Wang, Yali Wang
AAAI 2026 Oral
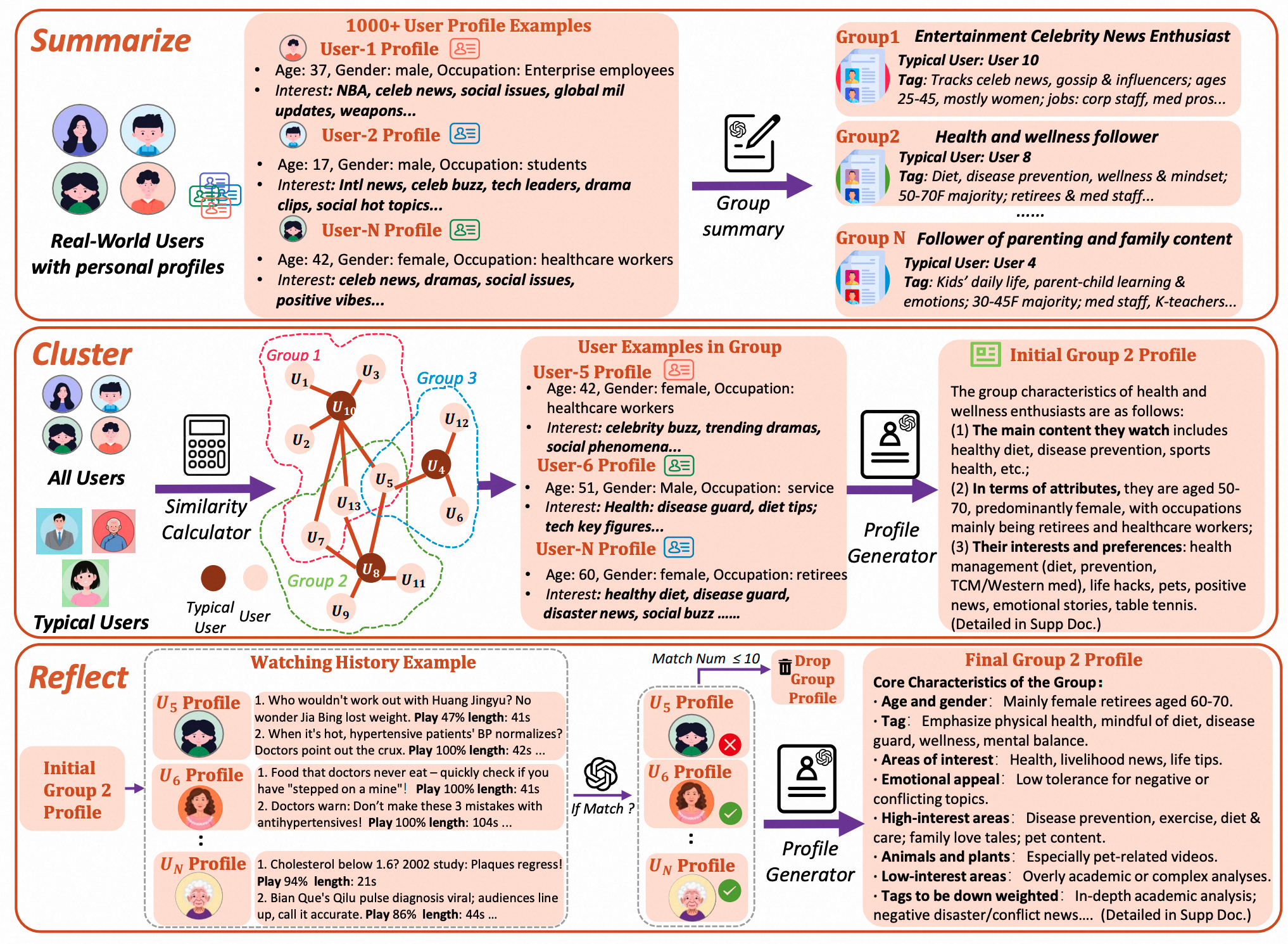
G-UBS: Towards Robust Understanding of Implicit Feedback via Group-Aware User Behavior Simulation
Boyu Chen*, Siran Chen*, Zhengrong Yue *, Kainan Yan, Chenyun Yu, Beibei Kong, Cheng Lei, Chengxiang Zhuo, Zang Li, Yali Wang
AAAI 2026
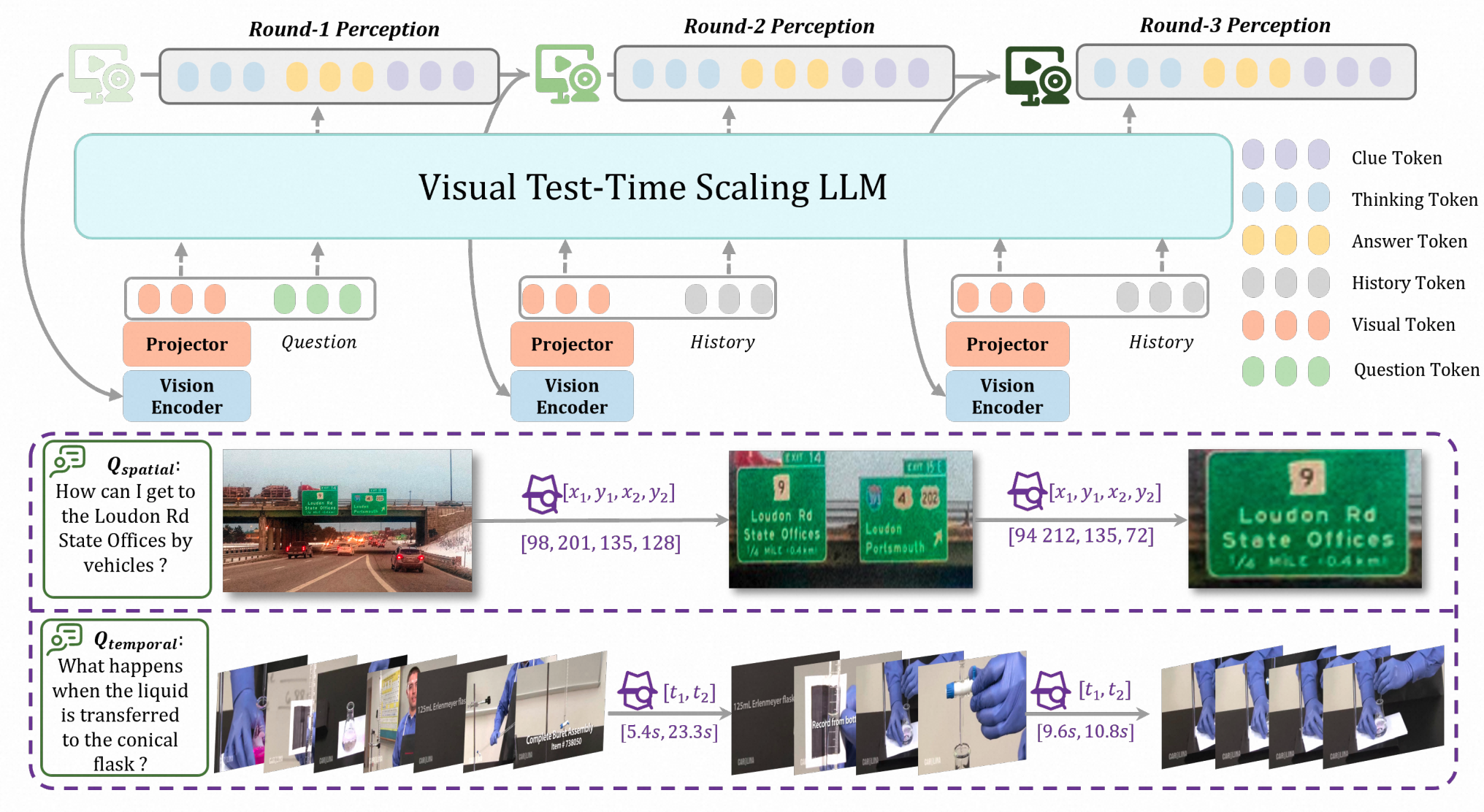
VTTS: Visual Test-Time Scaling to Reinforce Multimodal Reasoning by Iterative Perception
Ziang Yan*, Yinan He*, Xinhao Li*, Zhengrong Yue *, Xiangyu Zeng, Yali Wang, Yu Qiao, Limin Wang, Yi Wang
NeurIPS 2025
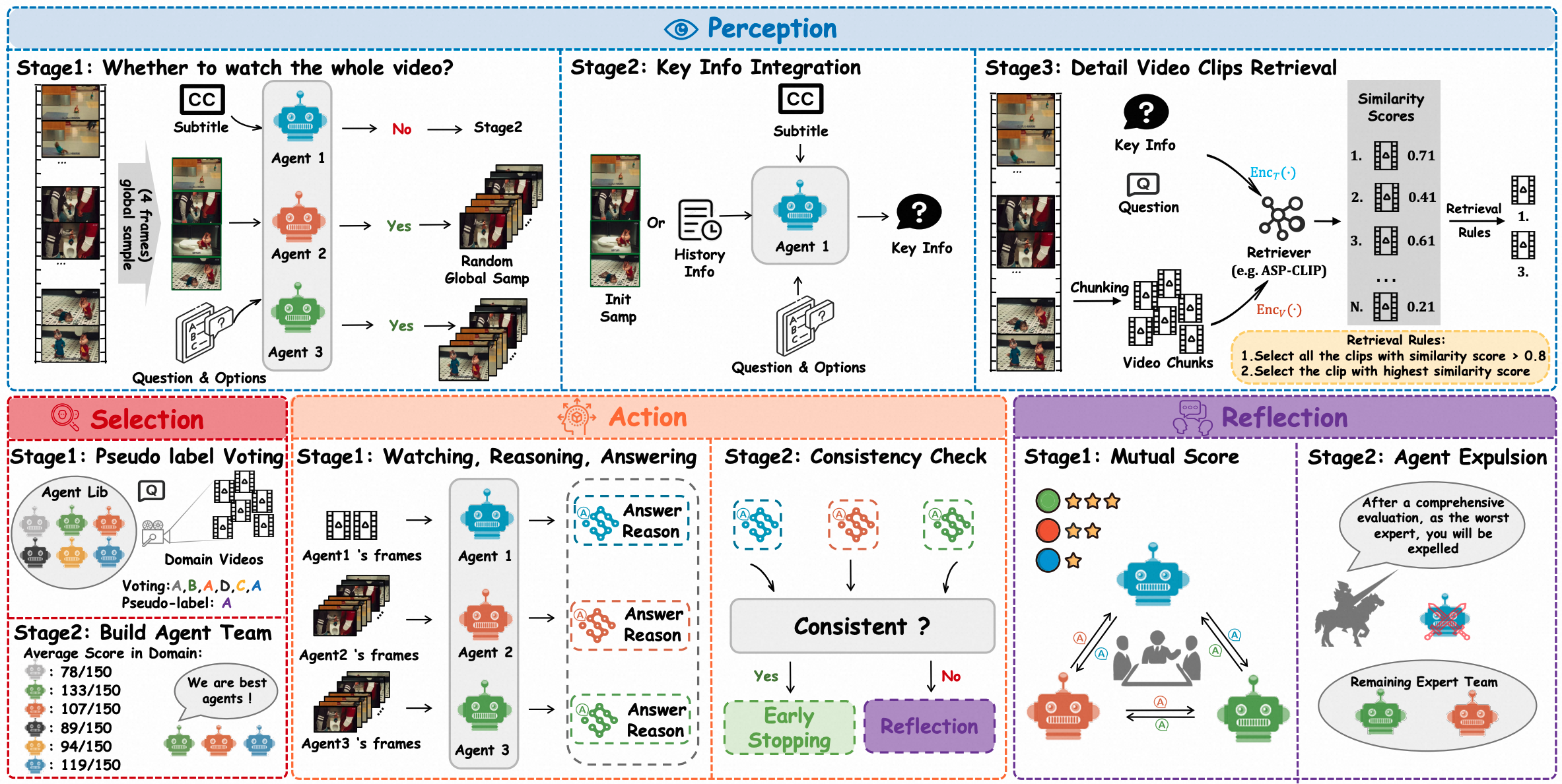
LVAgent: Dynamic Round-by-round MLLM Agent Collaboration for Long Video Understanding
Boyu Chen*, Zhengrong Yue *, Siran Chen*, Zikang Wang, Yang Liu, Peng Li, Yali Wang
ICCV 2025
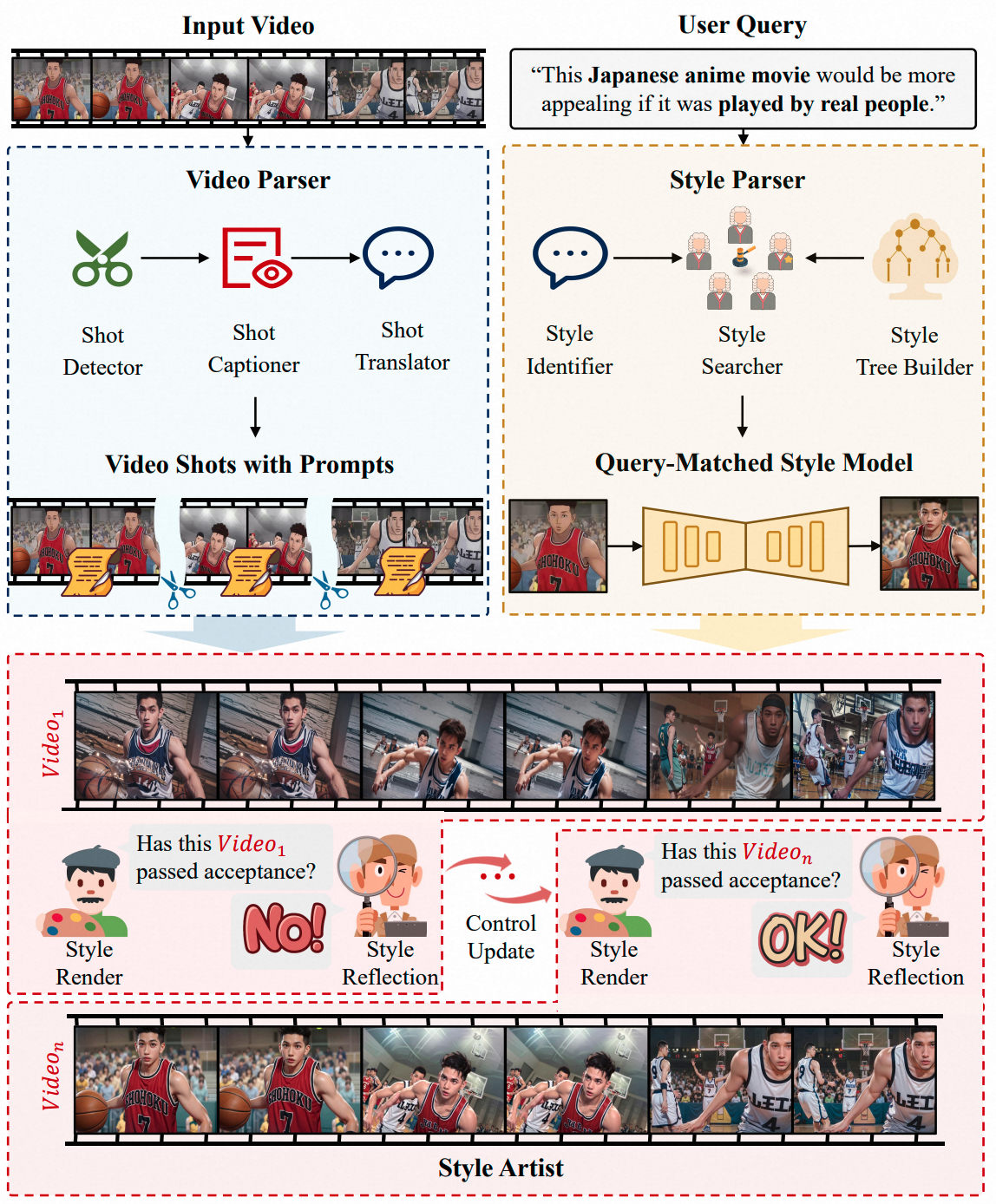
V-Stylist: Video Stylization via Collaboration and Reflection of MLLM Agents
Zhengrong Yue , Shaobin Zhuang, Kunchang Li, Yanbo Ding, Yali Wang
CVPR 2025
TimeSuite: Improving MLLMs for Long Video Understanding via Grounded Tuning
Xiangyu Zeng, Kunchang Li, Chenting Wang, Xinhao Li, Tianxiang Jiang, Ziang Yan, Songze Li, Yansong Shi, Zhengrong Yue , Yi Wang, Yali Wang, Yu Qiao, Limin Wang
ICLR 2025
Muses: 3D-Controllable Image Generation via Multi-Modal Agent Collaboration
Yanbo Ding, Shaobin Zhuang, Kunchang Li, Zhengrong Yue , Yu Qiao, Yali Wang
AAAI 2025
🤵🏻 InternshipsJune 2026 – Present
Unified MLLM; World Model.
Jan 2026 – June 2026
Representation Tokenizer; Unified Reward Model for Generation and Editing.
July 2025 – Dec 2025
Image Editing Model Based on Text-Image Interwoven Thought Chains; Unified Multimodal Model.
July 2024 – June 2025
Unified Tokenizer; Video Understanding and Generation tasks within multimodal frameworks.
Nov 2023 – June 2024
Explored video style editing based on MLLM Agents.
Sept 2023 – Nov 2023
Multilingual document question-answering large model for Galaxy Z-Fold based on RAG.
🏅 Honors & Awards2024 Outstanding Graduate of Beijing2023 National Scholarship (Top 1%)2023 Beijing Municipal Triple-Excellent Student 2022 1st Prize , National Robot and Artificial Intelligence Competition2022 1st Prize , National University Student Intelligent Vehicle Competition🤝 Academic Services📋 Conference Reviewer: CVPR 2026, ECCV 2026 📰 Journal Reviewer: IEEE TPAMI